先來說說AI是甚麼,人工智慧(AI)是指讓機器展現出與人類智慧相似的能力和行為的領域,重點在於思考與理解的能力。
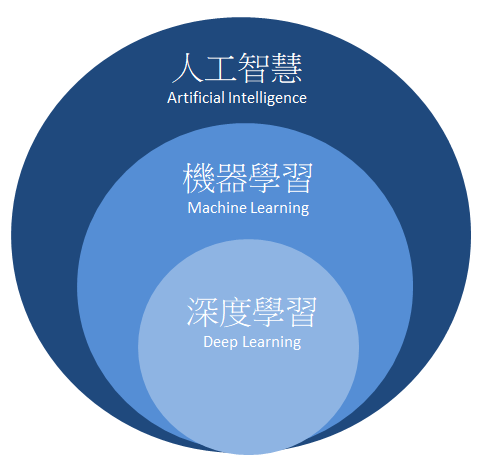
而機器學習是AI的一個子集,關係圖如下,它是通過讓機器從數據中學習和改進,自動提取模式、規則和知識,從而實現各種任務,例如圖像識別、語音辨識、自然語言處理等。
AI工程師有哪些?
資料分析師/數據分析師(Data Analyst)
資料分析師是負責收集、整理、分析和解釋數據的專業人員。主要使用統計和分析工具(清洗與分析),用圖表以展現數據中的模式、趨勢和關聯性(視覺化處理),進而提供對市場或公司的資料觀察結果。
需要了解的知識有:
- Matplotlib(常用)
- 統計學
- Seaborn
友情推薦:粉專-資料科學家的工作日常
資料工程師(Data Engineer)
資料工程師是負責設計、構建、維護和處理大規模數據的專業人員,需要把凌亂的資料轉成乾淨的資料,他們主要關注的是數據的流動、轉換和儲存(資料庫)。
需要了解的知識有:
- SQL database(SEL, Structured Query Language結構化查詢語言)
- Python(資料處理)
- Machine Learning
資料科學家(Data Scientist)
與資料分析師類似,一樣需要對資料進行清洗、分析、視覺化,不過更注重在於構建機器學習模型並訓練用於分析或是預測數據。
需要了解的知識有:
- PyTorch or TensorFlow
- 統計學
- 製作model(模型)
把問題化為函數
函數
函數,其實與數學上所說的函數一樣,即為function之意。
X 是定義域,Y 是值域,每一個 X 裡的元素,都要對應到 Y 裡的一個元素,而且只能對到一個。
用人話說,就是函數(function)是一個解答本,X是所有可能的題目(問題), Y 則是所有可能的答案。 函數的定義就是讓所有的題目都要有解答,並且是唯一的答案。
AI解決問題的過程
1.先問一個問題
一個問題有很多不同的問法,有時我們不能直接問這個問題,而是要換一種方式來問。
「問一個好問題」是人工智慧中最重要的部分之一了!
2.把問題化成函數的形式
所有的問題都需要有解答,我們需要函式來讓我們得到答案。
3.收集歷史資料
接著,AI需要蒐集「考古題」,經過大量收集歷史數據後,才能讓解答本越來越完善。
但AI就像班上那些背科很強的同學,他也會把考古題背起來,但如果遇到沒有看過的題目,他就會回答得非常離譜,這種狀況叫做過適或過度擬合(overfitting)。
4.打造一個函數學習機
這是使AI有思考能力的轉捩點,透過機器學習(machine learning)或神經網路(neural network)等方法來建構函數學習機,經過大量的資料學習過後,直到找到一個最好的參數來滿足我們所想要的函式,函數學習機就完成了。
舉例來說,我們想要找到最適直線y = wx + b,當我們決定好(w, b) = (2, 3)時,函數學習機就完成了
5.訓練
最後要訓練函數學習機,每次的訓練都會調整我所設定的參數,使函式更接近理想函式。
以最適直線來舉例,實際的數據也不一定會在最適直線上,那我們需要知道差的值到底是多少。就會透過損失函數來計算誤差,所以好的函數會希望損失函數越來越小。
損失函數有很多種,例如我們高中學過的最小平方法
補充一下,使用平方是為了避免負值,那就可能有人問了,那為甚麼不用絕對值呢?這是因為在更高維度的時候可能就不只有一個維度的正負了,再者,平方後也可以擴大離散差距,也能讓更方便應用微積分。
資料的處理
步驟與流程
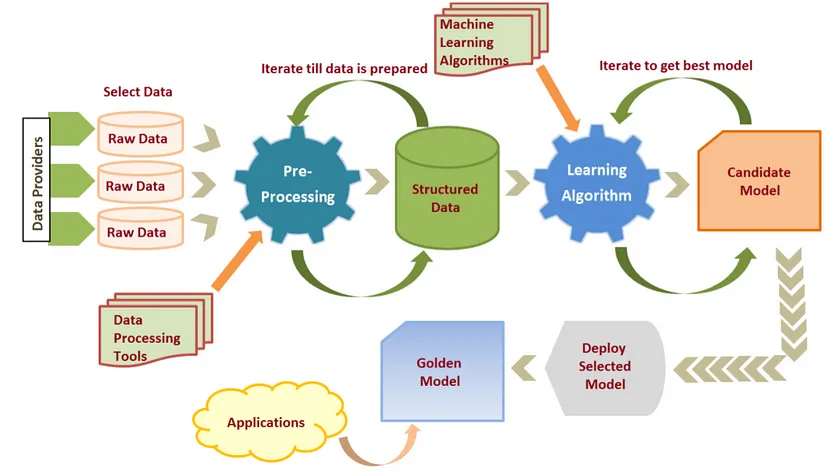
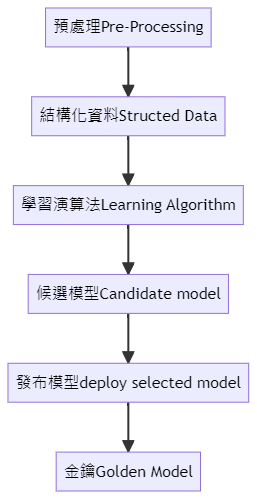
預處理的目的?
- 去除雜質(不必要的東西)
- 將資料轉換成方便電腦閱讀的形式
甚麼是候選模型?
訓練出來會有很多個模型,假設有100個模型,在這裡我們可能會選出最好的三個模型,作為我們的候選模型。最後再選出一位最佳候選模型,作為Golden Model(金鑰模型)。
機器學習(ML)演算法
分類與分群
分類 Classification
就是將物品分類至已經存在的類別
以函數表示會像這樣:
分類的結果稱為標籤(Label),也就是Y = function
判斷結果的資料叫做特徵(Feature),也就是x1,x2…。
簡單來說,就是將特徵(Feature)分類到已知的種類資訊,得到標籤(Label)
分群 Clustering
將物品分成至尚未存在的類別
其他跟分類一樣,
分群的結果稱為標籤(Label)
判斷結果的資料叫做特徵(Feature)
簡單來說,就是將特徵(Feature)分群到未知的種類資訊,得到標籤(Label)
機器學習類別
| 監督式學習 | 非監督式學習 | 半監督式學習 | 強化式學習 | |
|---|---|---|---|---|
| 資料來源 | 有標記(labeled) | 無標記(labeled) | 混合有標記與無標記 | 與環境互動 |
| 方法 | 將已知迴歸分析 | 從未知尋找既定模式(例如K平均演算法) | 提升模型正確率 | 透過正面回饋與負面回饋尋找最大效益 |
| 優點 | 準確率高 | 不需要標籤 | 標註成本低、數量少 | 效率較高 |
| 缺點 | 需要大量人力作業 | 可能造成不具重要性的特徵被過度放大 | 可能造成不具重要性的特徵被過度放大 | 容易過度擬合 |
About this Post
此文章由 IHCT 所撰寫,版權聲明:CC BY-NC 4.0.